lunes, 23 de enero de 2012
viernes, 20 de enero de 2012
Conceptos Avanzados de Base de Datos y BD orientado a Objetos
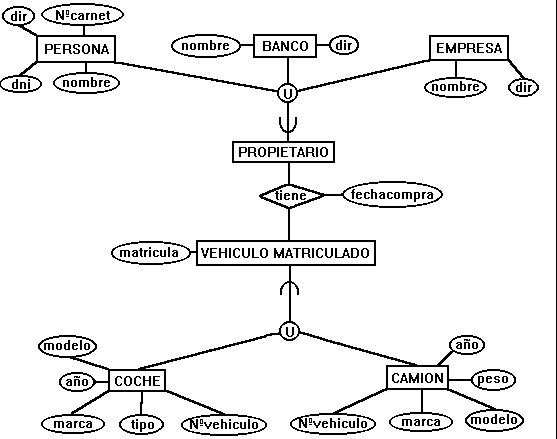
Diferencias entre el modelo ER y el modelo ER extendido
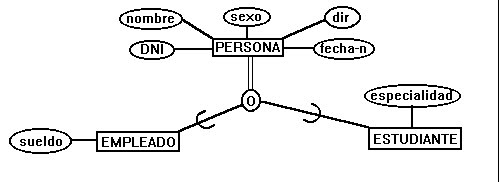
Detrás de las diferencias sintácticas de varias extensiones está el enriquecimiento semántico acerca de las relaciones entre las entidades. Por ejemplo, muchos de los cambios sintácticos propuestos giran alrededor de la generalización/especialización, una clara indicación de las mejoras semánticas. En el EER se añaden los conceptos de generalización, agregación, clase y subclase.

Clases, superclases, especialización y retícula

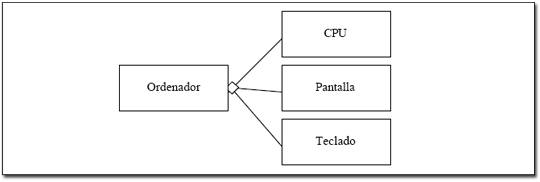
Generalización, agregación y asociación
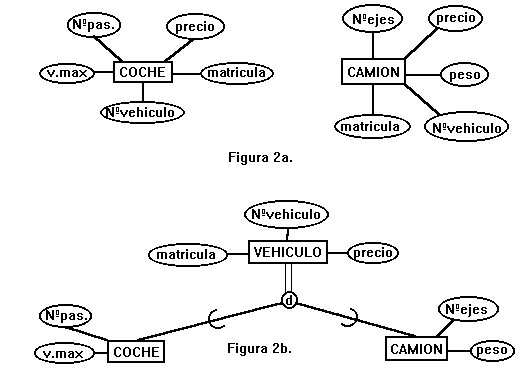
Modelado de datos con especialización y generalización

Categorías y la categorización
Base de datos orientada a objetos



Jerarquía de clases y Herencia

Sistema Gestor de Base de Datos Orientada a Objetos - SGBDOO

EER-OO en Base de Datos Orientada a Objetos
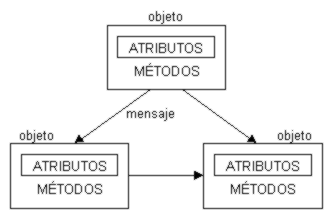
Objetos complejos estructurados, no estructurados y extensibilidad de tipos

jueves, 19 de enero de 2012
El modelo de base de datos de red y de Datos Jerarquico
Estructura de una base de datos de red
Una estructura de datos en red, o estructura plex, es muy similar a una estructura jerárquica, de hecho no es más que un súper conjunto de ésta. Al igual que en la estructura jerárquica, cada nodo puede tener varios hijos pero, a diferencia de ésta, también puede tener varios padres. La Figura muestra una disposición plex. En esta representación, los nodos C y F tienen dos padres, mientras que los nodos D, E, G y H tienen sólo uno
 .
.- Elemento de datos: Unidad de datos más pequeña que se puede referenciar. Puede ser de distintos tipos, y puede definirse como dependiente de valores de otros elementos (datos derivados).
- Agregado de datos: Se asemeja a los campos de un fichero o a los atributos de otros modelos.
- Registro: Colección nominada de elementos de datos. Unidad básica de acceso y manipulación. Se asemeja a los registros en ficheros y a las entidades en el modelo E/R.
- Conjunto (SET): Colección nominada de dos o más tipos de registros que establece una vinculación entre ellos. Origen de muchas restricciones. Las interrelaciones 1:N se representan aquí mediante SET.
- Área: Subdivisión nominada del espacio direccionable de la base de datos que contiene ocurrencias de registros.
- Clave de base de datos: Identificador interno único para cada ocurrencia de registro.
Restricciones en el modelo de base de datos de red
El modelo Codasyl está basado en el modelo en red general, pero a diferencia de este, es un modelo utilizado. Esto es debido a que Codasyl ha incluido restricciones inherentes que hacen que sea posible su implementación y que se obtenga un alto rendimiento del sistema.
Las restricciones son las siguientes:
- Solo se admiten tipos de interrelaciones jerárquicas de dos niveles (propietario y miembro). Si se admite la combinación de varios SET para generar jerarquías multinivel.
- En el nivel propietario solo se permite un tipo de registro.
- En el mismo SET no se permite que a un registro ser a la vez propietario y miembro, no está admitida la reflexividad. Aunque esta restricción se eliminó con el tiempo, los productos basados en Codasyl la siguen utilizando.
- Una misma ocurrencia de miembro no puede pertenecer en un mismo tipo de SET a más de un propietario. Esto hace que se simplifique la implementación física de los SET, ya que sus ocurrencias se pueden organizar como una cadena.
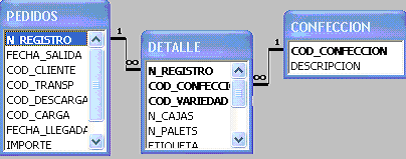
Uso de la transformación ER-Red para el diseño de bases de datos de red
Un registro equivale a una entidad y un campo a un atributo del modelo entidad relación. Los campos contienen exclusivamente valores atómicos. Una liga es una relación que se establece solamente entre dos registros; es decir; debe utilizarse una liga para cada relación entre una pareja de registros.
{kind=link}

El caso anterior muestra la transformación del modelo entidad relación al modelo de red para una relación simple donde no existen atributos descriptivos en la relación.
Programación de una base de datos de red
clave: string[7]
nombreM: string[25]
cred: string[2];
end;
type alumno = record
nombre: string[30];
control: string[8];
materia: Materia; {Enlace a materia}
end;
Estructura del modelo jerárquico
1) SEGMENTO PADRE: Es aquél que tiene descendientes, todos ellos localizados en el mismo nivel.

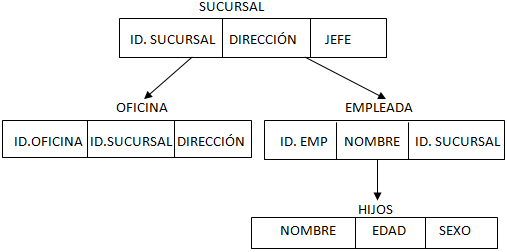
SEGMENTO RAÍZ: El segmento raíz de una base de datos jerárquica es el padre que no tiene padre. La raíz siempre es única y ocupa el nivel superior del árbol.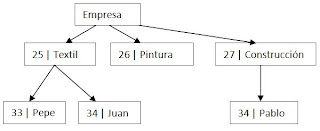
La raiz en el ejemplo sería: "empresa".
Una OCURRENCIA de un segmento de una base de datos jerárquica es el conjunto de valores particulares que toman todos los campos que lo componen en un momento determinado.
Un REGISTRO de la base de datos es el conjunto formado por una ocurrencia del segmento raíz y todas las ocurrencias del resto de los segmentos de la base de datos que dependen jerárquicamente de dicha ocurrencia raíz.
La relación PADRE/HIJO en la que se apoyan las bases de datos jerárquicas, determina que el camino de acceso a los datos sea ÚNICO; este camino, denominado CAMINO SECUENCIA JERÁRQUICA, comienza siempre en una ocurrencia del segmento raíz y recorre la base de datos de arriba a abajo, de izquierda a derecha y por último de adelante a atrás.
El esquema es una estructura arborescente compuesta de nodos, que representan las entidades, enlazados por arcos, que representan las asociaciones o interrelaciones entre dichas entidades.
La estructura del modelo de datos jerárquico es un caso particular de la del modelo en red, con fuertes restricciones adicionales derivadas de que las asociaciones del modelo jerárquico deben formar un árbol ordenado, es decir, un árbol en el que el orden de los nodos es importante. Una estructura jerárquica, tiene las siguientes características:
- El árbol se organiza en un conjunto de niveles.
- El nodo raíz, el más alto de la jerarquía, se corresponde con el nivel 0.
- Los arcos representan las asociaciones jerárquicas entre dos entidades y no tienen nombre, ya que no es necesario porque entre dos conjuntos de datos sólo puede haber una interrelación.
- Mientras que un nodo de nivel superior (padre) puede tener un número ilimitado de nodos de nivel inferior(hijos), al nodo de nivel inferior sólo le puede corresponder un único nodo de nivel superior. en otras palabras, un progenitor o padre puede tener varios descendientes o hijos, pero un hijo sólo tiene un padre.
- Todo nodo, a excepción del nodo raíz, ha de tener obligatoriamente un padre.
- Se llaman hojas los nodos que no tienen descendientes.
- Se llama altura al número de niveles de la estructura jerárquica.
- Se denomina momento al número de nodos.
- El número de hojas del árbol se llama peso.
- Sólo están permitidas las interrelaciones 1:1 ó 1:N
- Cada nodo no terminal y sus descendientes forman un subárbol, de forma que un árbol es una estructura recursiva.
- El árbol se suele recorrer en preorden; es decir, raíz, subárbol izquierdo y subárbol derecho.
Entre las restricciones propias de este modelo se pueden resaltar
A) Cada árbol debe tener un único segmento raíz.
B) No puede definirse más de una relación entre dos segmentos dentro de un árbol.
C) No se permiten las relaciones reflexivas de un segmento consigo mismo.
D) No se permiten las relaciones N:M.
E) No se permite que exista un hijo con más de un padre.
F) Para cualquier acceso a la información almacenada, es obligatorio el acceso por la raíz del árbol, excepto en el caso de utilizar un índice secundario.
G) El árbol debe recorrer siempre de acuerdo a un orden prefijado: el camino jerárquico.
H) La estructura del árbol, una vez creada, no se puede modificar.
Vinculos entre padre-hijo
El modelo jerárquico facilita relaciones padre-hijo, es decir, relaciones 1:N (de uno a varios) del modelo relacional. Pero a diferencia de éste último, las relaciones son unidireccionales. En justicia, dichas relaciones son hijo-padre, pero no padre-hijo. Por ejemplo, el registro de un empleado (nodo hijo) puede relacionarse con el registro de su departamento (nodo padre), pero no al contrario. Esto implica que solamente se puede consultar la base de datos desde los nodos hoja hacia el nodo raíz. La consulta en el sentido contrario requiere una búsqueda secuencial por todos los registros de la base de datos (por ejemplo, para consultar todos los empleados de un departamento). En las bases de datos jerárquicas no existen índices que faciliten esta tarea.
Obsérvese que, a priori, no existen relaciones N:M (de muchos a muchos) en el modelo jerárquico. Salvo que se simulen mediante varias relaciones 1:N. No obstante, esto puede provocar problemas de inconsistencia, ya que el gestor de base de datos no controla estas relaciones.

Restricciones del modelo jerárquico
No se garantiza la inexistencia de registros duplicados. Esto también es cierto para los campos "clave". Es decir, no se garantiza que dos registros cualesquiera tengan diferentes valores en un subconjunto concreto de campos.
Integridad referencial
No existe garantía de que un registro hijo esté relacionado con un registro padre válido. Por ejemplo, es posible borrar un nodo padre sin eliminar antes los nodos hijo, de manera que éstos últimos están relacionados con un registro inválido o inexistente..
Desnormalización
Este no es tanto un problema del modelo jerárquico como del uso que se hace de él. Sin embargo, a diferencia del modelo relacional, las bases de datos jerárquicas no tienen controles que impidan la desnormalización de una base de datos. Por ejemplo, no existe el concepto de campos clave o campos únicos.
La desnormalización permite ingresar redundancia de una forma controlada, seguir a una serie de pasos conlleva a:
- Combinar las relaciones
- Duplicar los atributos no claves
- Introducción de grupos repetitivos
- Crear tablas de extracción
Cuando se debe desnormalizar:
- Se debe desnormalizar para optimizar el esquema relacional
- Para hacer referencia a la combinación de 2 relaciones que forman una sola relación

Transformación de E/R en modelo de datos jerárquico

A) Interrelaciones 1:N con cardinalidad mínima 1 en la entidad padre. En este caso no existe ningún problema y el esquema jerárquico resultante será prácticamente el mismo que en el ME/R.
B) Interrelaciones 1:N con cardinalidad mínima 0 en el registro propietario. El problema es que podrían existir hijos sin padre, por lo que o se crea un padre ficticio para estos casos o se crean dos estructuras arborescentes.
La primera estructura arborescente tendrá como nodo padre el tipo de registro A y como nodo hijo los identificadores del tipo de registro B. De esta forma no se introducen redundancias, estando los atributos de la entidad B en la segunda arborescencia, en la cual sólo existiría un nodo raíz B sin descendientes.
C) Interrelaciones N:M
La solución es muy parecida, creándose también dos arborescencias.
La solución es independiente de las cardinalidades mínimas. Se podría suprimir, en la primera arborescencia o en la segunda, el registro hijo, pero no se conservaría la simetría.
D) Interrelaciones reflexivas
La jerarquía a) se utilizaría siempre que se desee obtener la explosión.
La aplicación de estas normas de diseño evita la introducción de redundancias, así como la pérdida de simetría, pero complica enormemente el esquema jerárquico resultante que estará constituido por más de un árbol, lo que no resulta fácilmente comprensible a los usuarios.
Ejemplos de modelo de datos jerárquicos
 A continuación, el modelo de datos jerárquico de la figura anterior:
A continuación, el modelo de datos jerárquico de la figura anterior: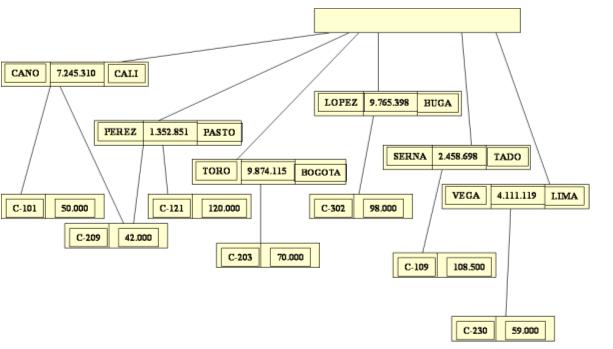 2) En este ejemplo presentaremos la estructura del modelo de datos jerárquico de un departamento de estudios de una univeridad.
2) En este ejemplo presentaremos la estructura del modelo de datos jerárquico de un departamento de estudios de una univeridad.
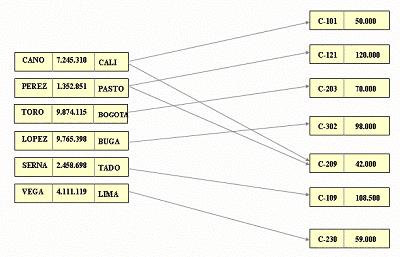
Ejemplo de modelo de datos de red
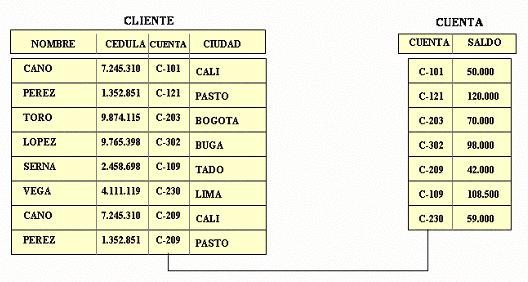 Esta modelo relacional transformada al modelo de red sería la siguiente:
Esta modelo relacional transformada al modelo de red sería la siguiente: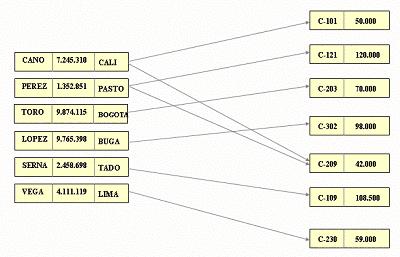
2)En este ejemplo, los tipos de registros son: CURSO, REQUISITO, OFERTA, PROFESOR y ESTUDIANTE. CURSO es el tipo de segmento raiz:
